diff, patch和quilt
diff和patch是在Linux环境为源代码制作和应用补丁的标准工具。diff可以比较文件或目录的差异,并将差异记录到补丁文件。
patch可以将补丁文件应用到源代码上。quilt也是一个制作和应用补丁的工具,它适合于管理较多补丁。quilt有自己的特有的工作方式。本文通过
简单的例子介绍这三个常用的工具。
0 示例工程
我们先准备一个用来做实验的工程,它包含若干子目录和文件。可以用find命令列出文件清单:
$ find old-prj/ -type f
old-prj/inc/def1.h
old-prj/inc/def2.h
old-prj/src/sys/sys1.c
old-prj/src/sys/sys1.h
old-prj/src/app/app1.c
old-prj/src/app/app2.c
old-prj/src/app/app2.h
old-prj/src/app/app1.h
old-prj/src/drv/drv1.h
old-prj/src/drv/drv2.c
old-prj/src/drv/drv1.c
old-prj/src/drv/drv2.h
old-prj/build/Makefile
find命令的"-type f"参数选择普通文件,可以省略掉目录。希望自己操作的读者可以下载这个示例工程。
1 diff和patch
1.1 比较一个文件
将old-prj.tar.bz2放到我们的工作目录,然后建立一个子目录,进入后解压示例工程:
$ mkdir test1; cd test1; tar xvjf ../old-prj.tar.bz2
用分号分隔多个命令可以节省篇幅。将old-prj复制到new-prj:
$ cp -a old-prj/ new-prj
让我们编辑一个文件。src/drv/drv1.h的内容本来是:
$ cat -n old-prj/src/drv/drv1.h
1 #ifndef DRV1_H
2 #define DRV1_H
3
4 #include "def1.h"
5
6 typedef struct {
7 int p1;
8 int p2;
9 int p3;
10 } App1;
11
12 void do_app1(void);
13
14 #endif
cat命令的"-n"参数可以增加行号。我们用vi将它修改成:
$ cat -n new-prj/src/drv/drv1.h
1 #ifndef DRV1_H
2 #define DRV1_H
3
4 #include "def1.h"
5
6 typedef struct {
7 int a;
8 int b;
9 } App1;
10
11 void do_app1(void);
12
13 #endif
现在可以用diff命令比较文件了:
$ diff -u old-prj/src/drv/drv1.h new-prj/src/drv/drv1.h
--- old-prj/src/drv/drv1.h 2008-03-01 12:59:46.000000000 +0800
+++ new-prj/src/drv/drv1.h 2008-03-01 13:07:14.000000000 +0800
@@ -4,9 +4,8 @@
#include "def1.h"
typedef struct {
- int p1;
- int p2;
- int p3;
+ int a;
+ int b;
} App1;
void do_app1(void);
diff程序按行比较文本文件。比较文件的diff命令格式是:
$ diff -u 旧文件 新文件
"-u"参数指定diff命令使用 unified 格式,这是一种最常用的格式,我们来看看它的含义。
1.2 diff的 unified 格式
以"---"开头的行是旧文件信息,以"+++"开头的行是新文件信息:
--- old-prj/src/drv/drv1.h 2008-03-01 12:59:46.000000000 +0800
+++ new-prj/src/drv/drv1.h 2008-03-01 13:07:14.000000000 +0800
unified 格式默认在变化部分的前后各显示三行上下文。在上例中,旧文件的7、8、9行被替换成新文件的7、8行。旧文件的变化部分是7-9行,前后多显示3行,
因此显示4-12行。新文件的变化部分是7-8行,前后多显示3行,因此显示4-11行。以"@@"包围的行指示补丁的范围:
@@ -4,9 +4,8 @@
'-4,9'中,'-'表示旧文件,'4,9'表示从第4行开始,显示9行,即显示4-12行。'+4,8'中,'+'表示新文件,'4,8'表示
从第4行开始,显示8行,即显示4-11行。"@@"行之后是上下文和变化的文本,其中'-'开头的行是旧文件特有的,'+'开头的行是新文件特有的,其
它行是两个文件都有的,即补丁的上下文。例如:
#include "def1.h"
typedef struct {
- int p1;
- int p2;
- int p3;
+ int a;
+ int b;
} App1;
void do_app1(void);
1.3 制作和应用补丁
所谓制作补丁就是diff的输出重定向到一个文件,这个文件就是补丁文件。例如:
$ diff -u old-prj/src/drv/drv1.h new-prj/src/drv/drv1.h>../drv1.diff
我们将old-prj解压到另一个目录,准备应用这个补丁:
$ cd ..; mkdir test2; cd test2; tar xvjf ../old-prj.tar.bz2; mv old-prj myprj; cd myprj
在真实场景中,test2目录通常是在用户2的电脑上。用户2可能不使用 old-prj 作为第一级目录的名字。例如:用户1的第一级目录名是 linux-2.6.23.14,
用户2的第一级目录名是linux。所以我们将 old-prj 改为 myprj 以模拟这种情况。
我们在 myprj 目录使用patch命令应用补丁:
$ patch -p1 < ../../drv1.diff
patching file src/drv/drv1.h
patch命令行中为什么没有出现要打补丁的文件?这是因为patch命令可以使用补丁文件中的文件信息:
--- old-prj/src/drv/drv1.h 2008-03-01 12:59:46.000000000 +0800
"-pn"参数(上例中n=1)中的n表示要从补丁文件的文件路径中去掉几层目录,可以理解为去掉几个'/'。例如:p1表示去掉一层目
录,"old-prj/src/drv/drv1.h"去掉一层就成为"src/drv/drv1.h"。patch命令在 myprj
目录找到"src/drv/drv1.h"后应用补丁。
我们通常都在代码树的上一层目录制作补丁,在代码树的根目录应用补丁。因此,最常用的patch命令格式是:
$ patch -p1 < 补丁文件
1.4 比较目录
我们回到test1目录,再对 new_prj 做一些改动。这次我们删除掉src/sys目录及其中的文件。再建立src/usr目录,并在该目录增加两个文件usr1.h和usr1.c。
$ cd ../../test1; rm -rf new-prj/src/sys; mkdir new-prj/src/usr
$ echo -e "#ifndef USR1_H\n#define USR1_H\n#include \"def1.h\"\n#endif">new-prj/src/usr/usr1.h
$ echo -e "#include \"usr1.h\"">new-prj/src/usr/usr1.c
echo命令的"-e"参数打开对转义符的支持,bash默认是不支持转义符的。
现在我们比较目录并制作补丁:
$ diff -Nur old-prj/ new-prj/ > ../prj.diff
读者可以cat这个补丁文件的内容。根据前面的介绍,读者应该能看懂补丁文件了吧。
比较目录的常用命令是:
$ diff -Nur 旧目录 新目录 > 补丁文件
或
$ diff -Naur 旧目录 新目录 > 补丁文件
"-u"参数前面已经介绍过了。"-N"参数将不存在的文件当作空文件。如果没有这个参数,补丁就不会包含孤儿文件(即另一方没有的文件)。"-r"参数表示比较子目录。"-a"参数表示将所有文件当作文本文件。
我们再准备一个目录来应用补丁:
$ cd ..; mkdir test3; cd test3; tar xvjf ../old-prj.tar.bz2; mv old-prj myprj; cd myprj
在源代码树的根目录应用补丁:
$ patch -p1 < ../../prj.diff
patching file src/drv/drv1.h
patching file src/sys/sys1.c
patching file src/sys/sys1.h
patching file src/usr/usr1.c
patching file src/usr/usr1.h
好了,读者可以用"diff -Nur"比较一下"test1/new_prj"和"test3/myprj",没有输出就表示完全相同。
$ cd ../..; diff -Nur test1/new-prj test3/myprj
1.5 很多的补丁...
一个大项目可能有不同开发者提供很多补丁。这些补丁可能还存在依赖关系,例如补丁B必须打在补丁A上。我们当然可以凭着程序员的“心细如发”去管理好这些补丁,不过有一个叫quilt的工具可以使我们轻松一些。当然,即使有工具的帮助,细心和认真也是必需的。
附录
为了简单起见,前面只介绍了一个"diff -Nur 老目录
新目录"的用法。有时候,新目录里只放了修改过的文件。这时可以不使用-N参数以忽略孤儿文件,即"diff -ur 老目录
新目录"。diff会输出孤儿文件的提示,我们可以删除或保留这些提示,它们对patch没有影响。
使用diff时可以用--exclude排除文件和目录,例如:
diff -ur -exclude=.* --exclude=CVS prj_old prj_new
上例排除了源代码树中以'.'开头的文件和所有CVS目录。其实对于CVS项目,可以直接在源代码树根目录中执行:
cvs diff -u3 > 补丁文件名
u3表示输出3行上下文的unified 格式。打补丁时在源代码树根目录中执行:
patch -p0 < 补丁文件名
"cvs diff"会自动忽略CVS项目外的文件。通过CVS的tag和补丁文件,我们可以方便地保存工作快照。
2 quilt
我们自己的项目可以用cvs或svn管理全部代码。但有时我们要使用其他开发者维护的项目。我们需要修改一些文件,
但又不能直接向版本管理工具提交代码。自己用版本管理工具重建整个项目是不合适的,因为大多数代码都是别人维护的,例如Linux内核。我们只是想管理好
自己的补丁。这时可以使用quilt。
2.1 基本概念
quilt是一个帮助我们管理补丁的程序。quilt的命令格式类似于cvs:
quilt 子命令 [参数]
0.46版的quilt有29个子命令。
掌握quilt的关键是了解使用quilt的流程。使用quilt时,我们会在一个完整的源代码树里工作。只要我们
在源代码树里使用了quilt命令,quilt就会在源代码树的根目录建立两个特殊目录:patches和.pc。quilt在patches目录保存它
管理的所有补丁。quilt用.pc目录保存自己的内部工作状态,用户不需要了解这个目录。
patches/series文件记录了quilt当前管理的补丁。补丁按照加入的顺序排列,早加入的补丁在前。quilt用堆栈的概念管理补丁的应用。
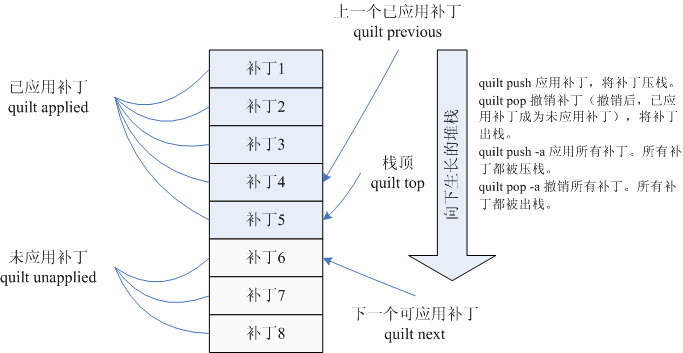
我们在应用补丁A前,必须先应用所有早于补丁A的补丁。所以,patches/series中的补丁总是从上向下应
用。例如:上图中,补丁1到补丁5是已经应用的补丁。我们可以将已应用的补丁想象成一个向下生长的堆栈,栈顶就是已应用的最新补丁。应用补丁就是将补丁入
栈,撤销补丁就是将补丁出栈。
我们在源代码树中作任何修改前,必须用"quilt add"命令将要修改的文件与一个补丁联系起来。在完成修改后,用"quilt refresh"命令将修改保存到已联系的补丁。下面我们通过一篇流程攻略来认识一下quilt的命令。
2.2 导入补丁
我们把 old-prj.tar.bz2 想象成Linux内核,我们把它解压后,进入代码树的根目录:
$ mkdir qtest; cd qtest; tar xvjf ../old-prj.tar.bz2; mv old-prj prj; cd prj
在修改代码前,我们通常要先打上官方补丁。在quilt中,可以用import命令导入补丁:
$ quilt import ../../prj.diff
Importing patch ../../prj.diff (stored as prj.diff)
执行improt命令后, prj 目录会多出一个叫 patches 的子目录:
$ find patches/ -type f
patches/prj.diff
patches/series
quilt在这个目录存放所有补丁和前面介绍的series文件。quilt的大多数命令都可以在代码树的任意子目录运行,不一定要从根目录运行。我们可以用applied命令查询当前已应用的补丁。
$ quilt applied
No patches applied
目前还没有应用任何补丁。unapplied命令查询当前还没有应用的补丁,top命令查询栈顶补丁,即已应用的最新补丁:
$ quilt unapplied
prj.diff
$ quilt top
No patches applied
我们可以使用push命令应用补丁,例如:
$ quilt push -a
Applying patch prj.diff
patching file src/drv/drv1.h
patching file src/sys/sys1.c
patching file src/sys/sys1.h
patching file src/usr/usr1.c
patching file src/usr/usr1.h
Now at patch prj.diff
push的"-a"参数表示应用所有补丁。在使用push命令后,prj 目录会多了一个叫.pc的隐含子目录。quilt用这个目录保存内部状态,用户不需要了解这个目录。应用补丁后,我们再使用applied、unapplied和top命令查看:
$ quilt applied
prj.diff
$ quilt unapplied
File series fully applied, ends at patch prj.diff
$ quilt top
prj.diff
2.3 修改文件
我们必须将对源代码树所作的任何改动都和一个补丁联系起来。add命令将文件的当前状态与补丁联系起来。add命令的格式为:
quilt add [-P 补丁名] 文件名
如果未指定补丁名,文件就与栈顶补丁联系起来。目前,我们的栈顶补丁是官方补丁。我们不想修改这个补丁,可以用new命令新建一个补丁:
$ quilt new drv_p1.diff
Patch drv_p1.diff is now on top
$ quilt top
drv_p1.diff
$ quilt applied
prj.diff
drv_p1.diff
$ quilt unapplied
File series fully applied, ends at patch drv_p1.diff
然后用add命令向栈顶补丁添加一个准备修改的文件:
$ cd src/drv; quilt add drv2.h
File src/drv/drv2.h added to patch drv_p1.diff
add命令为指定补丁保存了指定文件的当前快照,当我们执行refresh命令时,quilt就会检查文件
的变化,将差异保存到指定补丁中。使用"quilt diff -z [-P 补丁名]
[文件名]"可以查看指定补丁指定文件的当前改动。省略-P参数表示查看当前补丁的改动,省略文件名表示查看所有改动。我们修改drv2.h后,执行
diff命令:
$ quilt diff -z
Index: prj/src/drv/drv2.h
===================================================================
--- prj.orig/src/drv/drv2.h 2008-03-02 13:37:34.000000000 +0800
+++ prj/src/drv/drv2.h 2008-03-02 13:38:53.000000000 +0800
@@ -1,7 +1,7 @@
-#ifndef APP1_H
-#define APP1_H
+#ifndef DRV2_H
+#define DRV2_H
-#include "def1.h"+#include "def2.h"
#endif
只要文件已经与我们希望保存改动的补丁联系过了,我们就可以多次修改文件。使用"quilt files
[补丁名]"命令可以查看与指定补丁关联的文件。使用"quilt files
-val"可以查看所有补丁联系的所有文件。"-v"参数表示更友好的显示,"-a"参数表示显示所有补丁,"-l"参数显示补丁名。例如:
$ quilt files
src/drv/drv2.h
$ quilt files -val
[prj.diff] src/drv/drv1.h
[prj.diff] src/sys/sys1.c
[prj.diff] src/sys/sys1.h
[prj.diff] src/usr/usr1.c
[prj.diff] src/usr/usr1.h
[drv_p1.diff] src/drv/drv2.h
"quilt refresh [补丁名]"刷新补丁,即将指定补丁的文件变化保存到补丁。省略文件名表示刷新栈顶补丁。我们refresh后,查看补丁文件:
$ quilt refresh
Refreshed patch drv_p1.diff
$ cat ../../patches/drv_p1.diff
Index: prj/src/drv/drv2.h
===================================================================
--- prj.orig/src/drv/drv2.h 2008-03-02 12:42:21.000000000 +0800
+++ prj/src/drv/drv2.h 2008-03-02 12:46:25.000000000 +0800
@@ -1,7 +1,7 @@
-#ifndef APP1_H
-#define APP1_H
+#ifndef DRV2_H
+#define DRV2_H
-#include "def1.h"
+#include "def2.h"
#endif
"quilt diff -z"命令不会显示已经保存的差异。"quilt diff"显示所有的差异,不管是否保存过。
2.4 再做几个补丁
在增加文件前,我们要先将准备增加的文件与补丁联系起来。我们新建一个补丁,然后新增两个文件src/applet/applet1.h和src/applet/applet1.c。
$ cd ..; quilt new more_p1.diff
Patch more_p1.diff is now on top
$ quilt add applet/applet.c
File src/applet/applet.c added to patch more_p1.diff
$ quilt add applet/applet.1
File src/applet/applet.1 added to patch more_p1.diff
看看我们增加的文件:
$ quilt files
src/applet/applet.1
src/applet/applet.c
哎呀,文件名写错了。我们可以用"remove"命令从补丁中删除关联文件:
$ quilt remove applet/applet.1
rm: remove write-protected regular empty file `.pc/more_p1.diff/src/applet/applet.1'? y
File src/applet/applet.1 removed from patch more_p1.diff
$ quilt remove applet/applet.c
rm: remove write-protected regular empty file `.pc/more_p1.diff/src/applet/applet.c'? y
File src/applet/applet.c removed from patch more_p1.diff
$ quilt files
$ quilt add applet/applet1.h
File src/applet/applet1.h added to patch more_p1.diff
$ quilt add applet/applet1.c
File src/applet/applet1.c added to patch more_p1.diff
$ quilt files
src/applet/applet1.c
src/applet/applet1.h
好了,现在可以创建新文件:
$ mkdir applet
$ echo -e "#ifndef APPLET1_H\n#define APPLET1_H\n#include \"def1.h\"\n#endif">applet/applet1.h
$ echo -e "#include \"applet1.h\"">applet/applet1.c
$ quilt refresh more_p1.diff
Refreshed patch more_p1.diff
刷新补丁后,我们再修改文件drv2.h。修改前一定要先将文件与准备保存改动的补丁联系起来:
$ quilt add drv/drv2.h
File src/drv/drv2.h added to patch more_p1.diff
$ vi drv/drv2.h
$ quilt diff -z drv/drv2.h
Index: prj/src/drv/drv2.h
===================================================================
--- prj.orig/src/drv/drv2.h 2008-03-02 14:19:35.000000000 +0800
+++ prj/src/drv/drv2.h 2008-03-02 14:31:28.000000000 +0800
@@ -1,7 +1,7 @@
#ifndef DRV2_H
#define DRV2_H
-#include "def2.h"
+#include "def1.h"
#endif
我们再新建一个补丁,然后删除两个文件。删除文件前也要先为文件建立关联:
$ quilt new more_p2.diff
Patch more_p2.diff is now on top
$ quilt add app/*
File src/app/app1.c added to patch more_p2.diff
File src/app/app1.h added to patch more_p2.diff
File src/app/app2.c added to patch more_p2.diff
File src/app/app2.h added to patch more_p2.diff
$ rm -rf app
$ quilt refresh
Refreshed patch more_p2.diff
我们再修改applet/applet1.h:
$ quilt edit applet/applet1.h
File src/applet/applet1.h added to patch more_p2.diff
$ quilt refresh
Refreshed patch more_p2.diff
"quilt edit"在调用"quilt add"后自动启动编辑器。用refresh命令刷新补丁。
对了,前面为more_p1.diff修改drv2.h后还没有刷新呢。我们查看修改并刷新:
$ quilt diff -z -P more_p1.diff
Index: prj/src/drv/drv2.h
===================================================================
--- prj.orig/src/drv/drv2.h 2008-03-02 14:19:35.000000000 +0800
+++ prj/src/drv/drv2.h 2008-03-02 14:31:28.000000000 +0800
@@ -1,7 +1,7 @@
#ifndef DRV2_H
#define DRV2_H
-#include "def2.h"
+#include "def1.h"
#endif
Warning: more recent patches modify files in patch more_p1.diff
$ quilt refresh more_p1.diff
More recent patches modify files in patch more_p1.diff. Enforce refresh with -f.
$ quilt refresh -f more_p1.diff
Refreshed patch more_p1.diff
quilt会抱怨更新的补丁修改了补丁more_p1.diff的文件。这是在说more_p2.diff修改了applet1.h。我们知道这和我们要刷新的drv2.h没关系,所以可以用-f参数强制刷新。
2.5 管理补丁
series命令可以查看series文件中的补丁:
$ quilt series
prj.diff
drv_p1.diff
more_p1.diff
more_p2.diff
"quilt patches 文件名"显示修改了指定文件的所有补丁,例如:
$ quilt patches drv/drv2.h
drv_p1.diff
more_p1.diff
"quilt annotate 文件名"显示指定文件的修改情况,它会指出哪个补丁修改了哪一行。例如:
$ quilt annotate drv/drv2.h
1 #ifndef DRV2_H
1 #define DRV2_H
2 #include "def1.h"
#endif
1 drv_p1.diff
2 more_p1.diff
我们可以使用push和pop命令应用补丁或撤销补丁,例如:
$ quilt pop -a
Removing patch more_p2.diff
Restoring src/app/app1.c
Restoring src/app/app2.c
Restoring src/app/app2.h
Restoring src/app/app1.h
Restoring src/applet/applet1.h
Removing patch more_p1.diff
Restoring src/drv/drv2.h
Removing src/applet/applet1.h
Removing src/applet/applet1.c
Removing patch drv_p1.diff
Restoring src/drv/drv2.h
Removing patch prj.diff
Restoring src/sys/sys1.c
Restoring src/sys/sys1.h
Restoring src/drv/drv1.h
Removing src/usr/usr1.c
Removing src/usr/usr1.h
No patches applied
$ quilt top
No patches applied
$ quilt next
prj.diff
$ quilt previous
No patches applied
"quilt pop -a"撤销所有补丁。top命令显示栈顶命令,即当前应用的最新的补丁。next命令显示下一个可以应用的补丁。previous显示上一条应用过的补丁。"push 补丁A"将从上到下依次应用所有早于补丁A的补丁,最后应用补丁A。例如:
$ quilt push more_p1.diff
Applying patch prj.diff
patching file src/drv/drv1.h
patching file src/sys/sys1.c
patching file src/sys/sys1.h
patching file src/usr/usr1.c
patching file src/usr/usr1.h
Applying patch drv_p1.diff
patching file src/drv/drv2.h
Applying patch more_p1.diff
patching file src/applet/applet1.c
patching file src/applet/applet1.h
patching file src/drv/drv2.h
Now at patch more_p1.diff
$ quilt top
more_p1.diff
$ quilt next
more_p2.diff
$ quilt previous
drv_p1.diff
"quilt push -a"应用所有补丁:
$ quilt push -a
Applying patch more_p2.diff
patching file src/app/app1.c
patching file src/app/app1.h
patching file src/app/app2.c
patching file src/app/app2.h
patching file src/applet/applet1.h
Now at patch more_p2.diff
"quilt graph -all"可以为栈顶补丁的依赖关系生成dot文件。Graphviz的dot可以根据dot文件产生图片,例如:
$ quilt graph --all > ../../more_p2.dot
$ cd ../..; dot -Tpng more_p2.dot -o more_p2.png
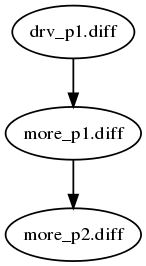
2.6 发布补丁
只要将patches目录打包发布就可以了。例如:
$ cd prj; tar cvjf prj-0.1-patches.tar.bz2 patches; mv prj-0.1-patches.tar.bz2 ../..
用户先下载、解压补丁包对应的源代码树:
$ cd ../..; mkdir user; cd user; tar xvjf ../old-prj.tar.bz2; mv old-prj/ prj
然后下载、解压补丁:
$ cd ../..; tar xvjf prj-0.1-patches.tar.bz2; cd user/prj
最后把补丁目录链接到源代码树的patches目录,然后应用所有补丁:
$ ln -sfn ../../patches/ patches
$ quilt push -a
Applying patch prj.diff
patching file src/drv/drv1.h
patching file src/sys/sys1.c
patching file src/sys/sys1.h
patching file src/usr/usr1.c
patching file src/usr/usr1.h
Applying patch drv_p1.diff
patching file src/drv/drv2.h
Applying patch more_p1.diff
patching file src/applet/applet1.c
patching file src/applet/applet1.h
patching file src/drv/drv2.h
Applying patch more_p2.diff
patching file src/app/app1.c
patching file src/app/app1.h
patching file src/app/app2.c
patching file src/app/app2.h
patching file src/applet/applet1.h
Now at patch more_p2.diff
3 结束语
在上面的流程攻略中,我们演示了19个quilt命令:add, annotate, applied,
diff, edit, files, graph, import, new, next, patches, pop, previous,
push, refresh, remove, series, top, unapplied。





